One of the goals of Open Spaces conferences is to turn "corridor conversations" into the focal point of the conference. This was aptly demonstrated at
CITCON ANZ when Richard Vowles introduced a topic we'd been discussing over kebabs the night before.
Richard has subsequently discussed the topic on the
Illegal Argument podcast. This post is an extension of the discussion.
The problemWhen running integration and acceptance tests, test failures may be caused by factors other than incorrect code. This is most apparent when performing end-to-end testing through to Enterprise Information Systems. A number of factors can cause the test to fail - system unavailable, test data not in required state.
It would be useful to categorise the failures by cause, for notification and reporting purposes. Developers should be notified of code-related issues, testers might be responsible for data issues, and sys ops for server errors. Over time it would also be useful to visualise how often server and data errors are occurring.
Richard provided the example:
Given a customer has been in arrears for over 90 days...
In order to run this test in an end-to-end environment, the test code has to get a customer in this state. Richard's system uses an AS/400 back-end, and it simply is not possible to automate the setup of a customer in this state. The test code may need to be configured with a specific customer id, or it may be smart enough to search for a customer in the required state.
Over time, the customer data may no longer be available. For example, periodic data refreshes may remove or update the customer details.
Richard's not the only one with this problem - I'm also seeing it on a current project.
The problem of finding adequate test data is exacerbated when the test updates the state:
Given a customer has been in arrears for over 90 days,
when her invoices are paid in full,
then her status is changed to black.
In this case, the destructive change to the customer's state means that the data is no longer suitable for running this test. The test needs to find a different customer in arrears the next time it is run. Since debtors are a finite resource, the test may be unrunnable at some stage.
Why run these fragile end-to-end tests?
With Agile Acceptance Testing (ATDD, BDD etc), the focus is on testing business examples that will prove to the customer that a feature is "done". Running the tests end-to-end provides the greatest assurance to the customer that the functional requirements are being met, and reduces the need for manual regression testing.
Depending on the project, it may be possible to implement these tests "under the covers" of the user interface, or using mocks for back-end functionality. We often use these approaches to drive the design of our code, possibly before the user interface or back-end are available. However, these approaches don't provide the full benefits that we get from end-to-end tests.
"Unrunnable" test result
In the past, I have tackled this issue by making assertions on the Given clause of the tests. If the test pre-conditions are not met, the test results in a failure.
The proposal made at CITCON is to introduce a new "Unrunnable" test result state. This state is neither success nor failure. The discussion led to introducing a new colour for this state, to differentiate it from red (failure) and green (success).
Triaging test resultsExtending the idea, it would be useful to be able to triage test failures into user-defined categories. Depending on the nature of the failure (and possibly the severity) the failure would be assigned a category.
The CI server would send failure notifications to a category-specific list. For example, system failures would be notified to sys ops, data issues to testers, and code issues to developers.
Each category would be displayed with a different failure colour, allowing the causes of test failures to be tracked over time.
For some categories, for example server errors, it may not be worthwhile continuing with the test run. The test runner could potentially be configured to abort the test run dependent on the category of the failure.
Comparison with Pending stateMany BDD and ATDD tools already model a separate Pending or Unimplemented state - displayed in yellow (Cucumber), or grey (Concordion). The pending state can be viewed as one of these test failure conditions ("code unavailable").
ExampleA test could be annotated as follows:
@Triage(nature="SERVER_ERROR", exception=HostUnavailableException.class)
public class ArrearsFixture() {
@Triage(nature="DATA_UNAVAILABLE",exception=NoDataException.class)
public Customer findCustomerInArrears(Condition condition) {
....
}
}
On Hudson, test failures might show up as:

clearly showing that there is an ongoing issue with server errors, impacting on the team's ability to adequately test the system. Intermittent data-releated issues are also causing some tests to be unrunnable.
I'm not aware of any test tools/frameworks currently offering this capability. Does anyone know of anything similar?
UPDATE:
1. This topic was discussed on the
Illegal Argument list. I liked Mark Derricutt's point:
It's my thought that the finer grained reporting you CAN get the better,
whether you make use of it depends on the project and problem space.
After all - Exception is good enough to be thrown for all errors right?
IllegalArgumentException, IOException, FileNotFoundException are all rather
"controversial, mean many things to many people, and cause inconsistency and
confusion" - but we need that differentiation of exceptions to separate out
a chain of responsibility.
We know this in our code, but I think we also need this for our
builds/tests.
 While the results show that the test is failing since Netherlands is displayed in the Google results, it would be helpful to see the actual results page. The screenshot extension allows us to hover over the failure to see an image of the browser page at the time the failure occurred.
While the results show that the test is failing since Netherlands is displayed in the Google results, it would be helpful to see the actual results page. The screenshot extension allows us to hover over the failure to see an image of the browser page at the time the failure occurred.
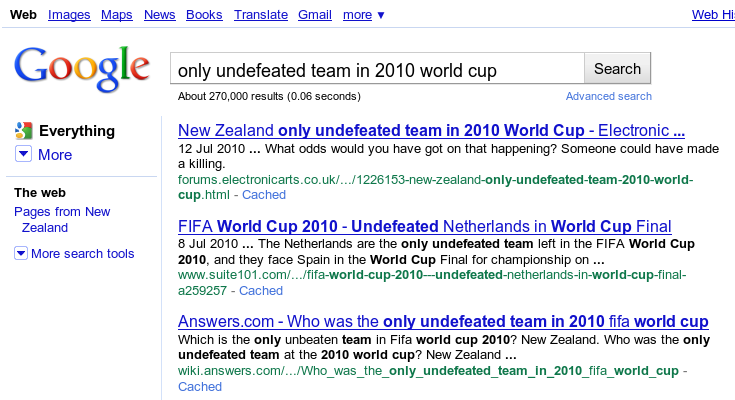 In this example, we've configured the extension to use WebDriver's
In this example, we've configured the extension to use WebDriver's 


